Data Parallelism v.s. Model Parallelism

For forward pass in data parallelism, the host (CPU/GPU#0) split the batch into micro-batches and scatter them to all devices (GPU#0, GPU#1, …, GPU#p-1). After that, a backward pass is conducted to compute the gradients for each micro-batch. The gradients are then gathered to the host, i.e , and update the weights for the network.
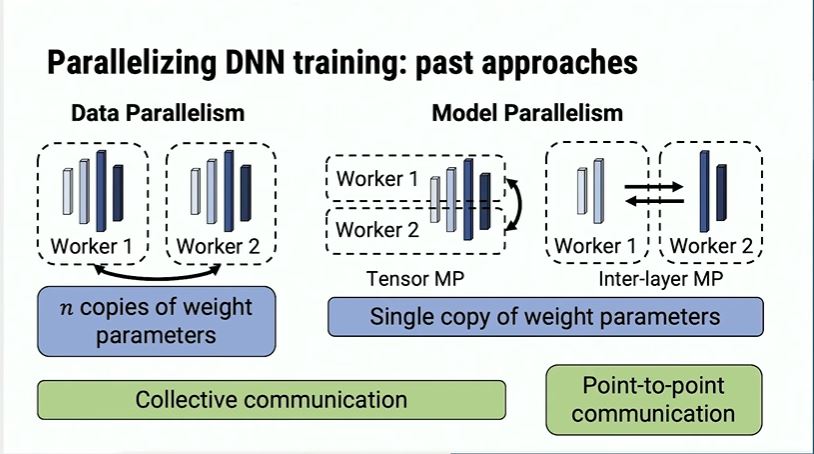
Model parallelism is far more complicated. There could be inter-layer parallelism (tensor parallelism), intra-layer parallelism (such as what Megatron-LM do in its multi-head self-attention layers) and pipeline parallelism(such as GPipe), as far as I know. Inter-layer parallelism needs more communications while inter-layer parallelism has less worries about that.
Data parallelism has its drawbacks. When the batch size is too large, say micro-batches split on 1024 GPUs, the training loss fails to converge quick enough. We need more epochs to finish our tasks. Thus, it is not wise to pile up GPUs to train.
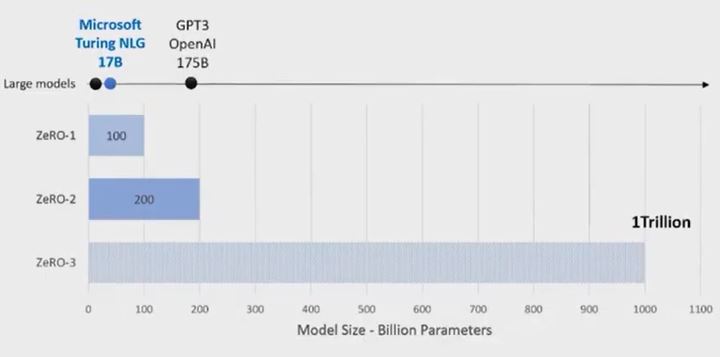
Also, when modern networks contain trillions of parameters, it is impossible to store the whole model inside a single GPU. So model parallelism is inevitable. For example, the DeepSpeed ZeRO-3 has made large scale training possible.
Pipeline Parallelism
Pipeline parallelism is a smart method to realize the inter-layer parallelism. I think it is less related to parallel computing, but more related to computer architecture, where pipeline is used to speed up the CPUs.
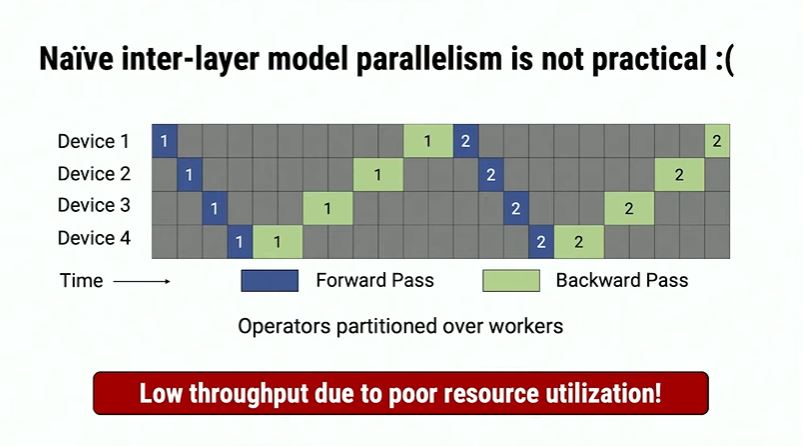
Naive inter-layer parallelism is an awkward idea of pipelining parallelism. The bubbles are too big, thus the throughput of a single GPU is very low.
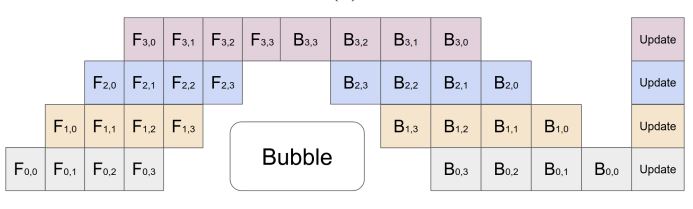
However, as is introduced in GPipe paper[3], an inter-layer parallelism could increase the throughput if multiple batches are pushed into the pipeline. ( for forward pass, for backward pass, for layer#, for batch#).
In Megatron-LM[1], a smarter pipeline is introduced.
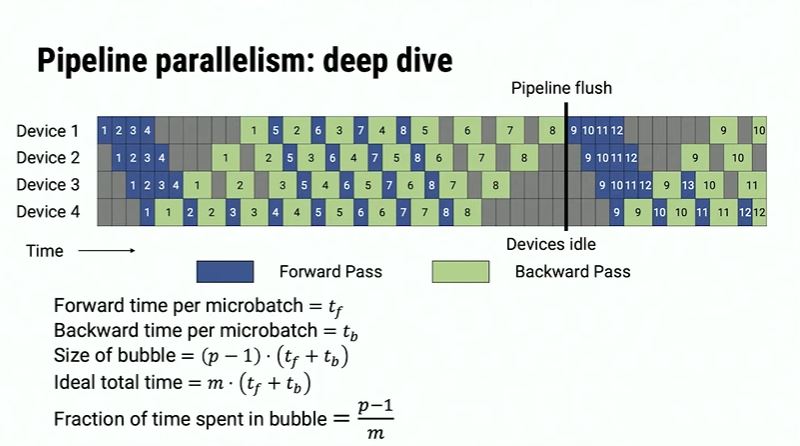
The great improvement is not an increase in throughput, but a reduction in memory requirements. In the above example, device 4 could free its memory concerning the batch as soon as the forward step is finished. This is called 1F1B(one forward pass followed by one backward pass). And the above schedule is non-interleaved.
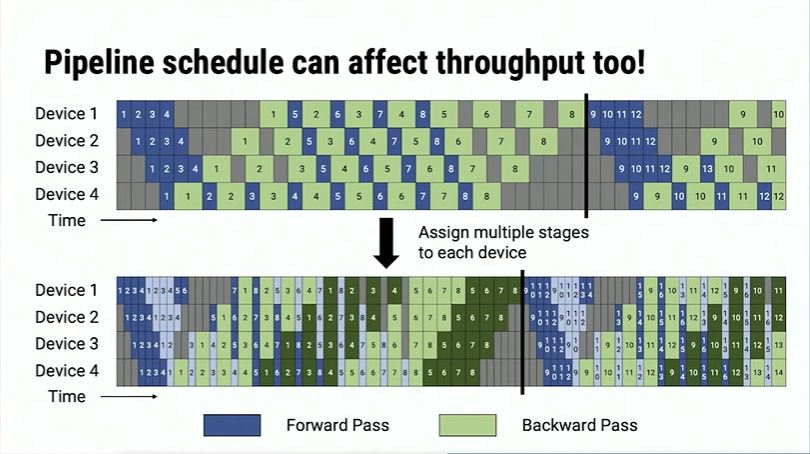
The model could also be folded, which means a single GPU can cope with multiple layers. This will enhance the throughput, as long as we organize the pipeline well. This is called interleaved.
Tensor Parallelism
Tensor 1D
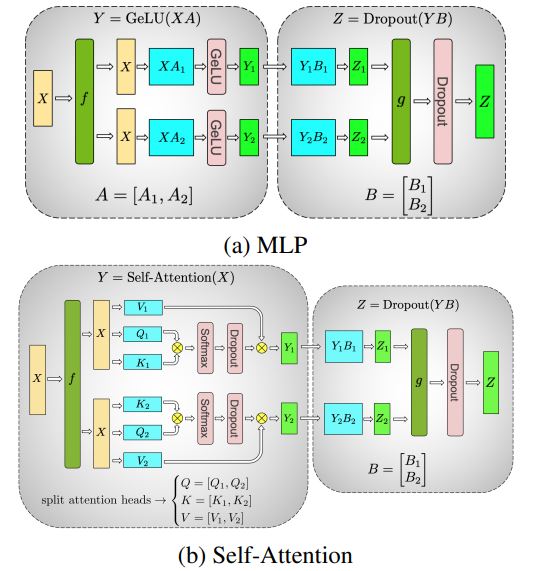
To compute the tensor multiplication , a naive way to parallelize it is to split it column-wise.
Another naive way is to split it row-wise.
Both of them are naive, but when we combine them together, it becomes a super combination of 2-layer MLP.
Notice that self-attention layer simply do some linear transformations and one activation on the split multi-heads, it is the same as a linear layer. This is what Megatron-LM does for its transformer block and 2-layer MLP.
Tensor 2D
Optimus [4] is stronger than Megatron because the tensor multiplication is improved using 2D parallelism. I am not familiar with the communication cost, but the SUMMA has better isoefficiency(?).
SUMMA optimize the matrix multiplication as follows. The host scatter one row of and one column of respectively to compute the outer product. Then the devices gather the tensor back to the host to compute an aggregation.

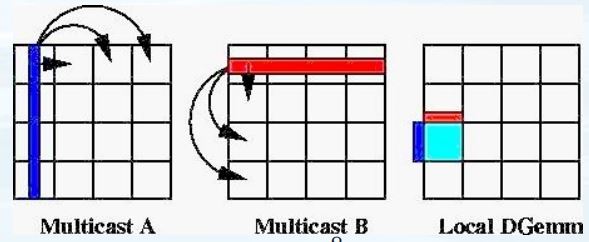
is different. Mark
Therefore,

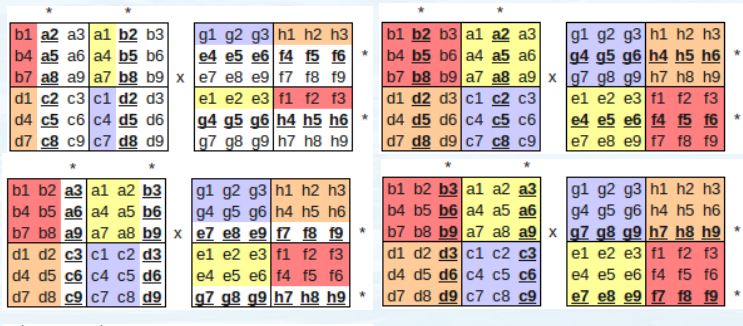
The block-wise parallelism is even more powerful. It could apply pipeline to the SUMMA algorithm.
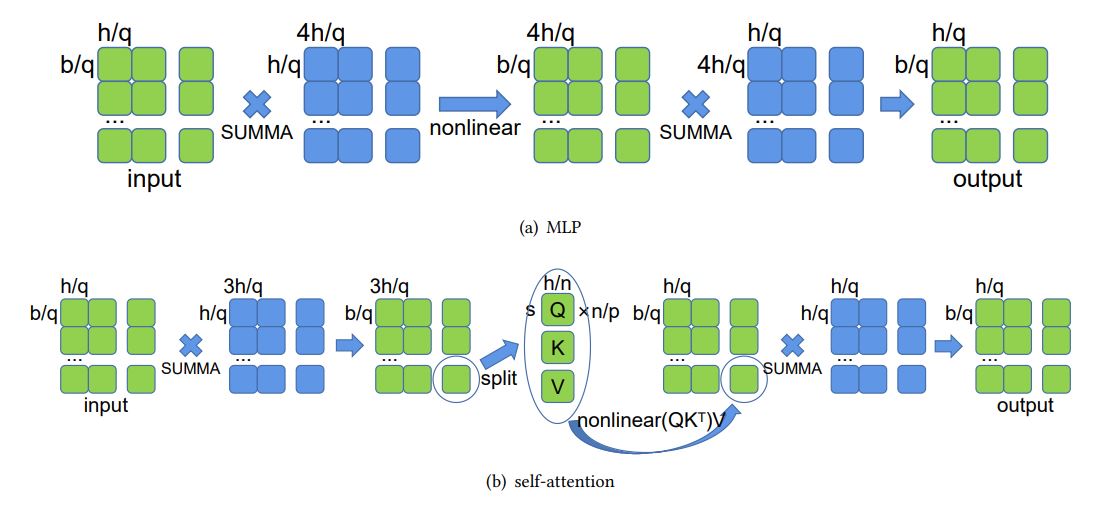
What is done in MLP can also be done in transformer. ( for hidden size, for batch size, q for # of GPUs).
Tensor 2.5D/3D
I find it hard to explain why.
Use Colossal-AI
See docs [9]. Here is the example of training BERT on 2 GPUs.
The BERT[6] uses sequence parallelism, which enables long sequence training. This is easy to understand, as the sequence is split into several subsequences for training.
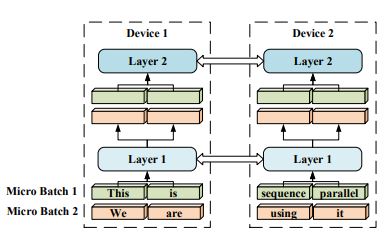
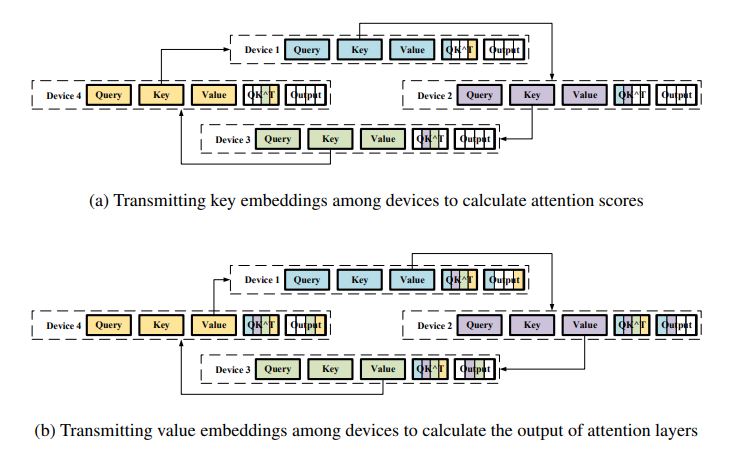
Each device GPU#i will be scattered with one subsequence of {query, key, value}, and a transmitting is required to all-gather the as a whole.
Reference:
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. https://arxiv.org/pdf/2104.04473.pdf (Youtube: https://www.youtube.com/watch?v=MO_CESBOXgo)
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. https://arxiv.org/pdf/1909.08053.pdf
- GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism. https://arxiv.org/pdf/1811.06965.pdf
- An Efficient 2D Method for Training Super-Large Deep Learning Models. https://arxiv.org/pdf/2104.05343.pdf
- 2.5-dimensional distributed model training. https://arxiv.org/pdf/2105.14500.pdf
- Sequence Parallelism: Long Sequence Training from System Perspective. https://arxiv.org/pdf/2105.13120.pdf
- https://zhuanlan.zhihu.com/p/366906920\
- https://cseweb.ucsd.edu/classes/sp11/cse262-a/Lectures/262-pres1-hal.pdf
- https://colossalai.org/docs/basics/define_your_config