minimize subject to c′xai′x≥bi,ai′x≤bi,ai′x=bi,xj≥0,xj≤0,i∈M1,i∈M2,i∈M3,j∈N1,j∈N2.
can be expressed compactly in both standard form and general form.
Definition 1.1.1 (General Form) A linear programming problem can be written as
minimize subject to c′xAx≥b
Definition 1.1.2 (Standard Form) A linear programming problem of the form
minimize subject to c′xAx=bx≥0
is said to be in standard form.
Polyhedron and convex sets
KEY: definition of polyhedron; definition of convex set.
We might as well revisit some definitions in convex optimization.
Definition 1.2 (Convexity and Concavity)
(a) A function f:ℜn↦ℜ is called convex if for every x,y∈ℜn, and every λ∈[0,1], we have
f(λx+(1−λ)y)≤λf(x)+(1−λ)f(y)
(b) A function f:ℜn↦ℜ is called concave if for every x,y∈ℜn, and every λ∈[0,1], we have
f(λx+(1−λ)y)≥λf(x)+(1−λ)f(y)
We also start with the formal definition of a polyhedron as well as a convex set.
Definition 1.3 (Polyhedron) A polyhedron is a set that can be described in the form {x∈ℜn∣Ax≥b}, where A is an m×n matrix and b is a vector in ℜm.
Definition 1.4 (Convex Set) A set S⊂ℜn is convex if for any x,y∈S, and any λ∈[0,1], we have λx+(1−λ)y∈S.
A polyhedron can either “extend to infinity,” or can be confined in a finite region. The definition that follows refers to this distinction.
Definition 1.5 (Boundedness) A set S⊂ℜn is bounded if there exists a constant K such that the absolute value of every component of every element of S is less than or equal to K.
The convex set also provide some interesting facts.
Theorem 1.1
(a) The intersection of convex sets is convex.
(b) Every polyhedron is a convex set.
(c) A convex combination of a finite number of elements of a convex set also belongs to that set.
Extreme Points and Basic Feasible Solutions
KEY: BFS = extreme point; geometric property of extreme point.
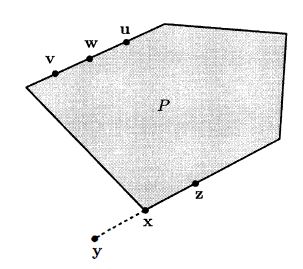
Our first definition defines an extreme point of a polyhedron as a point that cannot be expressed as a convex combination of two other elements of the polyhedron. This definition
is entirely geometric and does not refer to a specific representation of a polyhedron in terms of linear constraints.
Definition 1.6 (Extreme Point) Let P be a polyhedron. A vector x∈P is an extreme point of P if we cannot find two vectors y,z∈P, both different from x, and a scalar λ∈[0,1], such that x=λy+(1−λ)z.
To introduce the definition of basic feasible solution, we will first introduce the notation of active set.
Definition 1.7 (Active Set) If a vector x∗ satisfies ai′x∗=bi for some i in M1,M2, or M3, we say that the corresponding constraint is active at x∗. I={i∣ai′x∗=bi} is the set of indices of constraints that are active at x∗, or active set.
From basic linear algebra knowledge, we can have the following theorem.
Theorem 1.2 Let x∗ be an element of ℜn and let I={i∣ai′x∗=bi} be the active set of x∗. Then, the following are equivalent:
(a) There exist n vectors in the set {ai∣i∈I}, which are linearly independent.
(b) The span of the vectors ai,i∈I, is all of ℜn, that is, every element of ℜn can be expressed as a linear combination of the vectors ai,i∈I.
(c) The system of equations ai′x=bi,i∈I, has a unique solution.
We are now ready to provide an algebraic definition of a corner point, as a feasible solution at which there are n linearly independent active constraints. However, note that this procedure has no guarantee of leading to a feasible vector. Basic solution is a totally different notion with basic feasible solution.
Definition 1.8 (Basic Solution vs Basic Feasible Solution) Consider a polyhedron P defined by linear equality and inequality constraints, and let x∗ be an element of ℜn.
(a) The vector x∗ is a basic solution if:
(i) All equality constraints are active;
(ii) Out of the constraints that are active at x∗, there are n of them that are linearly independent.
(b) If x∗ is a basic solution that satisfies all of the constraints, we say that it is a basic feasible solution.
These two different definitions are, however, meant to capture the same concept geometrically and algebraically. This could be verified by contradiction.
Theorem 1.3 Let P be a nonempty polyhedron and let x∗∈P. Then, the following are equivalent:
(a) x∗ is an extreme point;
(b) x∗ is a basic feasible solution.
And we can easily derive the corollary.
Corollary 1.1 Given a finite number of linear inequality constraints, there can only be a finite number of basic or basic feasible solutions.
Standard Form Polyhedron
KEY: Theorem 1.4.
Recall that at any basic solution, there must be n linearly independent constraints that are active. Furthermore, every basic solution must satisfy the equality constraints Ax=b, which provides us with m linear independent active constraints. Therefore, there are n−m more constraints from n constraints of xi≥0.
Theorem 1.4 Consider the constraints Ax=b and x≥0 and assume that the m×n matrix A has linearly independent rows. A vector x∈ℜn is a basic solution if and only if we have Ax=b, and there exist indices B(1),…,B(m) such that:
(a) The columns AB(1),…,AB(m) are linearly independent;
(b) If i=B(1),…,B(m), then xi=0.
In this way, we can construct basic feasible solutions in the following way.
Choose m linearly independent columns AB(1),…,AB(m).
Let xi=0 for all i=B(1),…,B(m).
Solve the system of m equations Ax=b for the unknowns xB(1), …,xB(m).
We can also obtain an m×m matrix B, called a basis matrix, by arranging the m basic columns next to each other. We can similarly define a vector xB with the values of the basic variables. Thus,
The basic variables are determined by solving the equation BxB=b whose unique solution is given by
xB=B−1b
Existence of Extreme Points
KEY: has extreme point ↔ does not contain a line; a line has at most two intersection with a polyhedron.
We need the following definition
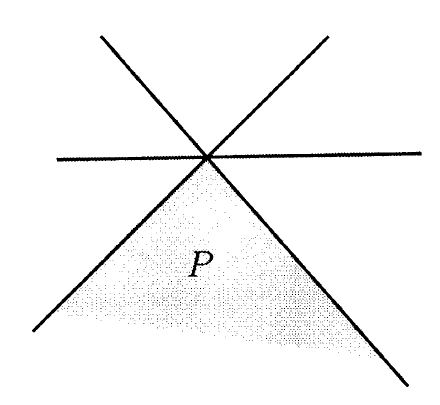
Definition 1.9 A polyhedron P⊂ℜn contains a line if there exists a vector x∈P and a nonzero vector d∈ℜn such that x+λd∈P for all scalars λ.
to formulate the following theorem.
Theorem 1.5 Suppose that the polyhedron P={x∈ℜn∣ai′x≥bi,i=1,…,m} is nonempty. Then, the following are equivalent:
(a) The polyhedron P has at least one extreme point.
(b) The polyhedron P does not contain a line.
(c) There exist n vectors out of the family a1,…,am, which are linearly independent.
Since a bounded polyhedron does not contain a line, we will have the following corollary
Corollary 1.2 Every nonempty bounded polyhedron and every nonempty polyhedron in standard form has at least one basic feasible solution.
Optimality of Extreme Points
If P={x∈ℜn∣Ax≥b} is the feasible set and v is the optimal value of the cost c′x. Then, Q={x∈ℜn∣Ax≥b,c′x=v} is also a polyhedron. With this, we can prove the following theorem that, as long as a linear programming problem has an optimal solution and as long as the feasible set has at least one extreme point, we can always find an optimal solution within the set of extreme points of the feasible set .
Theorem 1.6 Consider the linear programming problem of minimizing c′x over a polyhedron P. Suppose that P has at least one extreme point and that there exists an optimal solution. Then, there exists an optimal solution which is an extreme point of P.
A stronger result shows that the existence of an optimal solution can be taken for granted, as long as the optimal cost is finite.
Theorem 1.7 Consider the linear programming problem of minimizing c′x over a polyhedron P. Suppose that P has at least one extreme point. Then, either the optimal cost is equal to −∞, or there exists an extreme point which is optimal.
As any linear programming problem can be transformed into an equivalent problem in standard form, we will have the following corollary.
Corollary 1.3 Consider the linear programming problem of minimizing c′x over a nonempty polyhedron. Then, either the optimal cost is equal to −∞ or there exists an optimal solution.
Miscellaneous
One might be doubtful why A is always assumed to be full row rank. The following theorem shows that the full row rank assumption on the matrix A results in no loss of generality.
Theorem 1.8 Let P={x∣Ax=b,x≥0} be a nonempty polyhedron, where A is a matrix of dimensions m×n, with rows a1′,…,am′. Suppose that rank(A)=k<m and that the rows ai1′,…,aik′ are linearly independent. Consider the polyhedron
Q={x∣ai1′x=bi1,…,aik′x=bik,x≥0}
Then Q=P.
In some cases, the basic feasible solution is degenerate.
Definition 1.10 (Degeneracy) Consider the standard form polyhedron P={x∈ℜn∣Ax=b,x≥0} and let x be a basic solution. Let m be the number of rows of A. The vector x is a degenerate basic solution if more than n−m of the components of x are zero.
An important comment is that degeneracy is not a pure geometric property. That is to say, a degenerate basic feasible solution under one representation could be nondegenerate under another representation.
Simplex Method
Optimality conditions
**KEY: feasible direction; **
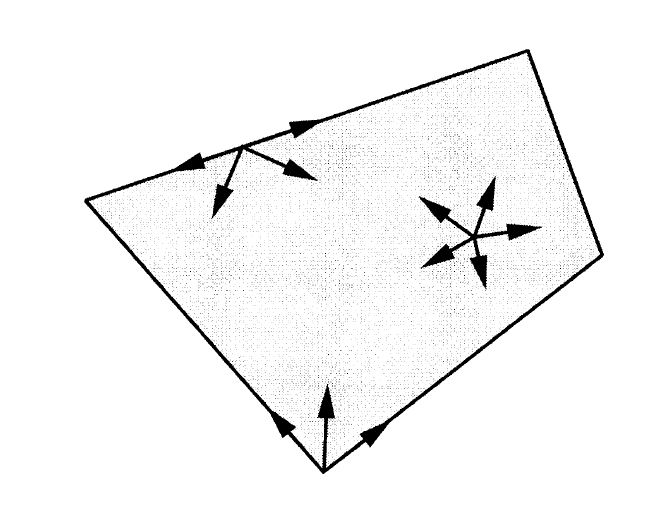
Suppose that we are at a point x∈P and that we contemplate moving away from x, in the direction of a vector d∈ℜn. Clearly, we should only consider those choices of d that do not immediately take us outside the feasible set.
Definition 2.1 (Feasible Direction) Let x be an element of a polyhedron P. A vector d∈ℜn is said to be a feasible direction at x, if there exists a positive scalar θ for which x+θd∈P.
Given that we are only interested in feasible solutions, we require A(x+θd)=b, and since x is feasible, we also have Ax=b. Thus, for the equality constraints to be satisfied for θ>0, we need Ad=0. If we want to move to adjacent extreme point, it must satisfy the condition that dj=1, and di=0 for all other non-basic indices i. Then,
Definition 2.2 (Reduced Cost) Let x be a basic solution, let B be an associated basis matrix, and let cB be the vector of costs of the basic variables. For each j, we define the reduced costcˉj of the variable xj according to the formula
cˉj=cj−cB′B−1Aj
With reduced cost, we can provide optimality conditions of linear programming.
Theorem 2.1 Consider a basic feasible solution x associated with a basis matrix B, and let c be the corresponding vector of reduced costs.
(a) If c≥0, then x is optimal.
(b) If x is optimal and nondegenerate, then c≥0.
Proof.
(a) We assume that c≥0, we let y be an arbitrary feasible solution, and we define d=y−x. Feasibility implies that Ax=Ay=b and, therefore, Ad=0. The latter equality can be rewritten in the form
BdB+i∈N∑Aidi=0
where N is the set of indices corresponding to the nonbasic variables under the given basis. Since B is invertible, we obtain
For any nonbasic index i∈N, we must have xi=0 and, since y is feasible, yi≥0. Thus, di≥0 and cˉidi≥0, for all i∈N. We conclude that c′(y−x)=c′d≥0, and since y was an arbitrary feasible solution, x is optimal.
(b) Suppose that x is a nondegenerate basic feasible solution and that cˉj<0 for some j. Since the reduced cost of a basic variable is always zero, xj must be a non-basic variable and cˉj is the rate of cost change along the j th basic direction. Since x is nondegenerate, the j th basic direction is a feasible direction of cost decrease, as discussed earlier. By moving in that direction, we obtain feasible solutions whose cost is less than that of x, and x is not optimal.
Simplex Method (Naive)
An iteration of the simplex method
In a typical iteration, we start with a basis consisting of the basic columns AB(1),…,AB(m), and an associated basic feasible solution x.
Compute the reduced costs cˉj=cj−cB′B−1Aj for all non-basic indices j. If they are all nonnegative, the current basic feasible solution is optimal, and the algorithm terminates; else, choose some j for which cˉj<0.
Compute u=−dB=B−1Aj. If no component of u is positive, we have θ∗=∞, the optimal cost is −∞, and the algorithm terminates.
If some component of u is positive, let
θ∗={i=1,…,m∣ui>0}minuixB(i).
Let ℓ be such that θ∗=xB(ℓ)/uℓ. Form a new basis by replacing AB(ℓ) with Aj. If y is the new basic feasible solution, the values of the new basic variables are yj=θ∗ and yB(i)=xB(i)−θ∗ui, i=ℓ.
If we define Bˉ(i)={B(i),j,i=ℓi=ℓ, which is the new basis of the new basic feasible solution. This can be verified by the following theorem.
Theorem 2.2
(a) The columns AB(i),i=ℓ, and Aj are linearly independent and, therefore, B is a basis matrix.
(b) The vector y=x+θ∗d is a basic feasible solution associated with the basis matrix B.
The problem of this naive implementation is that the matrix inverse has O(n3) complexity, thus resulting in O(m3+mn) computational effort per iteration. Nevertheless, simplex method is guaranteed convergence.
Theorem 2.3 (Convergence of Simplex Method) Assume that the feasible set is nonempty and that every basic feasible solution is nondegenerate. Then, the simplex method terminates after a finite number of iterations. At termination, there are the following two possibilities:
(a) We have an optimal basis B and an associated basic feasible solution which is optimal.
(b) We have found a vector d satisfying Ad=0,d≥0, and c′d<0, and the optimal cost is −∞.
Simplex Method (Revised)
Notice that since B−1B=I, we have the property that B−1AB(i) is the i th unit vector ei. Using this observation, we have
where u=−dB=B−1Aj. Since the result is the identity, we have QB−1B=I, which yields QB−1=B−1. We can update B−1 to B−1 by row operations with Q.
Q=⎣⎡1⋱−ulu1⋮uℓ1⋮−ulu1⋱1⎦⎤
This will reduce the operation per iteration to O(m2+mn).
Simplex Method (Tableau)
Another implementation of simplex method is called full tableau. Here, instead of maintaining and updating the matrix B−1, we maintain and update the m×(n+1) matrix
B−1[b∣A]
with columns B−1b and B−1A1,…,B−1An. This matrix is called the simplex tableau. Note that the column B−1b, called the zeroth column, contains the values of the basic variables.
It is customary to augment the simplex tableau by including a top row, to be referred to as the zeroth row. The entry at the top left corner contains the value −cB′xB, which is the negative of the current cost. The rest of the zeroth row is the row vector of reduced costs, that is, the vector c′=c′−cB′B−1A. Thus, the structure of the tableau is:
−cB′B−1bB−1bc′−cB′B−1AB−1A
Complexity
Memory Worst-case time Best-case time Full tableau O(mn)O(mn)O(mn) Revised simplex O(m2)O(mn)O(m2)
Finding an Initial Basic Feasible Solution (Two-Phase Algorithm)
Consider the problem
minimize subject to c′xAx=bx≥0
By possibly multiplying some of the equality constraints by −1, we can assume, without loss of generality, that b≥0. We now introduce a vector y∈ℜm of artificial variables and use the simplex method to solve the auxiliary problem
minimize subject to y1+y2+⋯+ymAx+y=bx≥0y≥0.
Initialization is easy for the auxiliary problem: by letting x=0 and y=b, we have a basic feasible solution and the corresponding basis matrix is the identity.
If x is a feasible solution to the original problem, this choice of x together with y=0, yields a zero cost solution to the auxiliary problem. Therefore, if the optimal cost in the auxiliary problem is nonzero, we conclude that the original problem is infeasible. Otherwise, the solution x will be a basic feasible solution.
Dual Simplex Method
The Dual Problem
Let A be a matrix with rows ai′ and columns Aj. Given a primal problem with the structure shown on the left, its dual is defined to be the maximization problem shown on the right:
Theorem 3.1 If we transform the dual into an equivalent minimization problem and then form its dual, we obtain a problem equivalent to the original problem.
And this theorem can be even stronger.
Theorem 3.2 Suppose that we have transformed a linear programming problem Π1 to another linear programming problem Π2, by a sequence of transformations of the following types:
(a) Replace a free variable with the difference of two nonnegative variables.
(b) Replace an inequality constraint by an equality constraint involving a nonnegative slack variable.
(c) If some row of the matrix A in a feasible standard form problem is a linear combination of the other rows, eliminate the corresponding equality constraint.
Then, the duals of Π1 and Π2 are equivalent, i.e., they are either both infeasible, or they have the same optimal cost.
Duality Theorem
We have discussed too much duality theorems in convex optimization course, so I will just list out several theorems for reference.
Theorem 3.3 (Weak duality) If x is a feasible solution to the primal problem and p is a feasible solution to the dual problem, then
p′b≤c′x
Theorem 3.4 (Strong duality) If a linear programming problem has an optimal solution, so does its dual, and the respective optimal costs are equal.
Theorem 3.5 (Complementary slackness) Let x and p be feasible solutions to the primal and the dual problem, respectively. The vectors x and p are optimal solutions for the two respective problems if and only if:
pi(ai′x−bi)=0,(cj−p′Aj)xj=0,∀i∀j
Dual Simplex Method
An iteration of the dual simplex method
A typical iteration starts with the tableau associated with a basis matrix B and with all reduced costs nonnegative.
Examine the components of the vector B−1b in the zeroth column of the tableau. If they are all nonnegative, we have an optimal basic feasible solution and the algorithm terminates; else, choose some ℓ such that xB(ℓ)<0.
Consider the ℓ th row of the tableau, with elements xB(ℓ),v1,…, vn (the pivot row). If vi≥0 for all i, then the optimal dual cost is +∞ and the algorithm terminates.
For each i such that vi<0, compute the ratio cˉi/∣vi∣ and let j be the index of a column that corresponds to the smallest ratio. The column AB(ℓ) exits the basis and the column Aj takes its place.
Add to each row of the tableau a multiple of the ℓ th row (the pivot row) so that vj (the pivot element) becomes 1 and all other entries of the pivot column become 0 .
Interior Point Method
Intro
There are three types of Interior Point Methods.
Affine Scaling Algorithm
Potential Reduction
Path Following ✌
Primal -> Barrier Method
Primal-Dual -> KKT System
In this chapter, we will consider the linear programming problem in standard form.
mins.tcTxAx=bx>0
Definition 4.1 Given polyhedron P={x∣Ax=b,x≥0}, the interior point of P is defined as {x∈P∣x>0}.
Primal Method
If we only consider the primal problem, we could integrates inequality constraints to the objective function using a logarithmic barrier ϕ(x)=∑i=1nlog(xi).
Definition 4.2 (Barrier Method) To solve the LP problem in standard form, we introduce a variable μ>0, and the problem can be reformulated as (Pμ),
mins.tcTx−μi=1∑nlog(xi)Ax=b
∀μ>0, ∃ unique x(μ) that solves (Pμ). When μ↓0, limμ→0x(μ)=x∗.
Primal-Dual Method
Intro
If we consider both the primal and dual problem, we could solve the KKT condition of the LP problem. Let us start with the KKT condition of the standard form.
⎩⎨⎧Ax=bA⊤y+s=cxisi=0i=1,⋯,2,n(x,s)>0
Define the non-linear system,
F(x,y,s)=⎝⎛Ax−bAT+s−cx∘s⎠⎞=0
Intuitively, we will use Newton method to solve non-linear systems. But here, we will first define a feasible set F={(x,y,s)∣Ax=b,ATy+s=c,(x,s)>0}, and a central path (x(μ),y(μ),s(μ))∈F, which converges to F(x,y,s)=0. The central path is given by,
F(x(μ),y(μ),s(μ))=⎝⎛Ax−bAT+s−cx∘s−μ⎠⎞=0
Definition 4.3 (Primal-Dual Method) Given the above central path. ∀μ>0, ∃ unique (x(μ),y(μ),s(μ))∈F that solves F(x(μ),y(μ),s(μ))=0. When μ↓0, limμ→0(x(μ),y(μ),s(μ))=(x∗,y∗,s∗).
Lemma 9.5 (of Bertsimas) If x∗=x(μ), y∗=y(μ) and s∗=s(μ) satisfy condition F(x(μ),y(μ),s(μ))=0, then they are also optimal solution to mincTx−μ∑i=1nlog(xi)s.tAx=b.
Proof: Let x be an arbitrary vector that satisfies x≥0 and Ax=b. The barrier function will be,
Note that the Newton method doesn’t guarantee global convergence, we need to avoid a single sixi<0. Otherwise, (xk,yk,sk) will fall out of the feasible set F={(x,y,s)∣Ax=b,ATy+s=c,x,s>0}.
Therefore, we will introduce an intermediate variable μ to keep both optimality and centrality, and solve s∘x=μ instead of s∘x=0.
Primal-Dual IPM-Naive:
Initial state:
(x0,y0,s0)∈F0τ=σμσ∈(0,1)μ=n1x⊤s
For k=0,1,⋯
Use Newton’s Method with starting point (xk,yk,sk) to solve F(x,y,s)=⎝⎛00σμke⎠⎞ and get,
(xk+1,yk+1,sk+1)∈F0
end
However, there is no necessity to compute the full Newton iteration. We can compute one Newton step and change the direction.
The following graph shows the path of convergence. If σ=1, τ=μ, the central path converges to μ. If σ=0, τ=0, the central path may not converge. We will discuss how to find σk and αk in the following section.
Path-Following Methods
For the sake of simplicity, we will define two types of neighborhoods.