Regular Expression (RE)
-
RE is a language for specifying text search strings.
-
Usage:
-
Concatenation
- The simplest RE is a sequence of simple characters , like /test/
- Putting characters in sequence is called concatenation.

-
Disjunction []
- Square brackets [ ] matches any single character from within the class
- Like /[wW]oodchuck/, /[A-Z]/

-
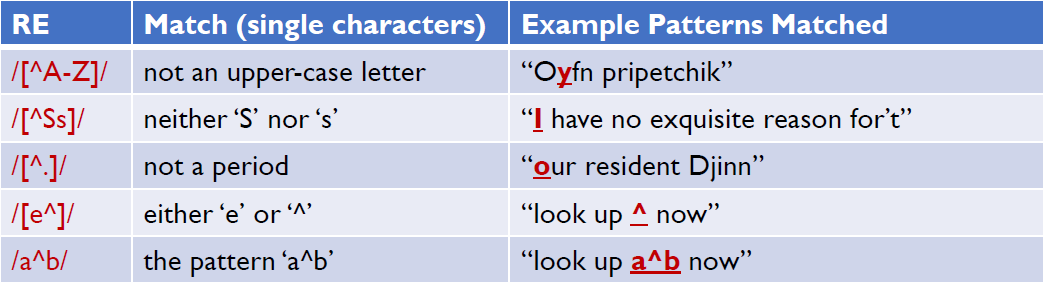
Negation ^
- If the caret ^ is the first symbol after the open square brace [, the resulting pattern is negated.
-
Counters ?*+
- Question mark ? matches zero or one appearance of the preceding item
- Kleene *(generally pronounced cleany star”) matches zero or more occurrences of the immediately previous character or regular expression
- Kleene + matches one or more occurrences of the immediately preceding character or regular expression.
-
Wildcard .
- The period (/./) is a wildcard expression that matches any single character (except a carriage return), e.g., /beg.n/ matches begin , beg’n , begun
-
Anchors ^$
- The caret ^ matches the start of a line
- The dollar sign $ matches the end of a line
-
Word Boundary \b \B
- A “word” for the purposes of a regular expression is defined as any sequence of digits , underscores , or letters , based on the definition of “words” in programming languages.
-
Disjunction |
-
-
Operator precedence
- Parenthesis ()
- Counters * + ? {}
- Sequences and anchors
- Disjunction |
-
The whole process is to fix two kinds of errors:
- False positives: strings that we incorrectly matched
- False negatives: strings that we incorrectly missed
Text Normalization and Edit Distance
-
Corpora
- Words
- Lemma
- the base form of a set of words in general having the same stem, the same major part of speech, and the same word sense.
- Wordform
- Inflectional: has the same word class
- Derivational: Changes of word class
- Word type vs word token
- Types are the number of distinct words in a corpus, or the size of the vocabulary.
- Tokens refer to the occurrences of the words
- Lemma
- Words
-
Text Normalization
- Case folding
- Lemmatization
- Morphology is the study of the way words are built up from smaller meaning bearing units called morphemes .
- Stemming: a simpler but cruder method, which mainly consists of chopping off word final stemming affixes.
-
Edit Distance

Parts of Speech and Named Entities
-
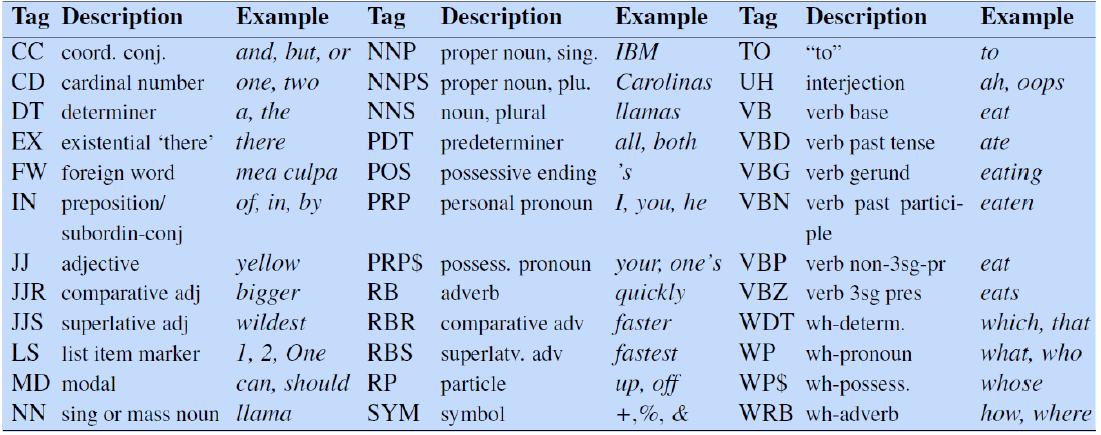
Parts of speech (POS) refers to word classes such as Noun, Verb, Adjective, etc.
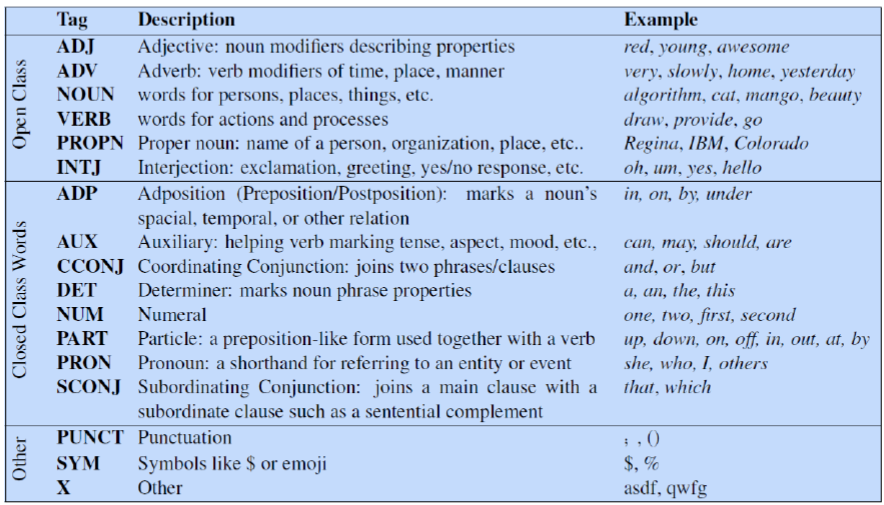
- Closed classes are those with relatively fixed membership , such as prepositions; new prepositions are rarely coined
- Nouns and verbs are among open classes new nouns and verbs like iPhone or fax are continually being created or borrowed
-
POS tagging is challenging
- Words are ambiguous
-
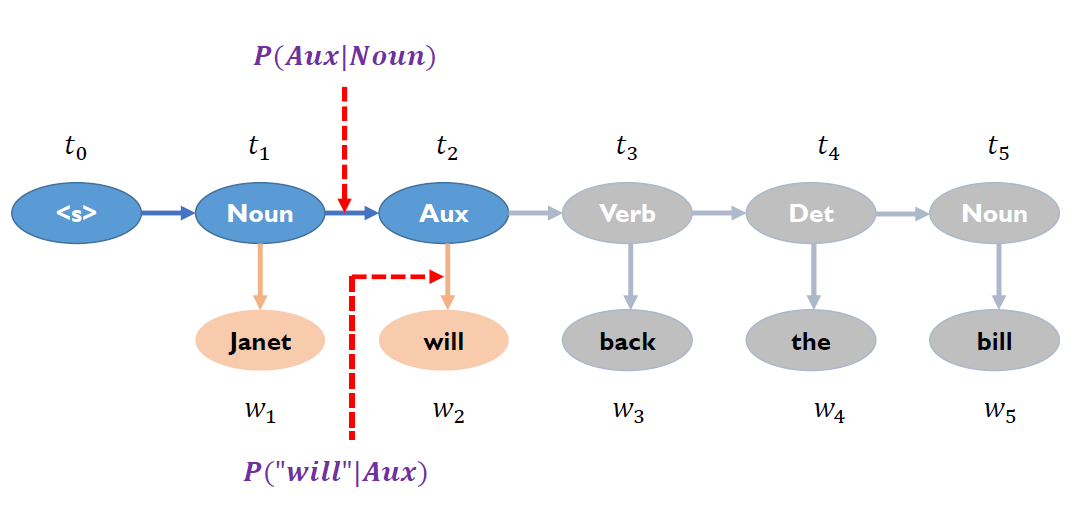
POS Tagging with Hidden Markov Model (HMM)

-
Objective:
-
Transformation:

-
-
Viterbi Algorithm

-
Named entity is proper name for person, location, organization, etc.
- The task of named entity recognition (NER) is to find spans of text that constitute proper names and tag the type of the entity.
-
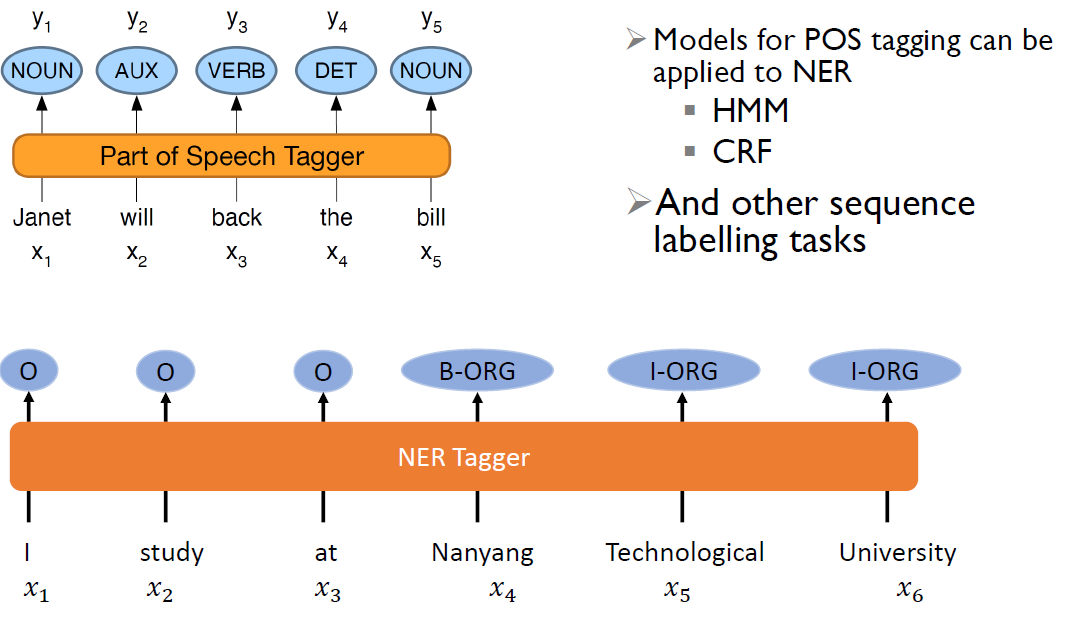
POS Tagging vs NER
-
Differences
- In POS tagging, each word gets one tag,
- In NER, we do not know the boundary of names, before we can label them
-
Similarities
- The same word may have different POS tags, like adj and adv for “Back”
- The same text span may have different NE types, like Victoria, Washington
- Both POS tagging and NER require surrounding words as context to make the tagging
- Both POS tagging and NER work at sentence level -> sequence labeling
-